When Your Upstream Goes Down: Building a Resilient Integration Microservice on Azure Service Bus
How extracting a fragile third-party integration into a queue-backed NestJS microservice eliminated upstream outages as a source of application downtime.
The Problem With Synchronous Integration at the Application Boundary
There is a specific class of production incident that is particularly demoralizing: one where your application goes down, your users lose hours of productivity, and the root cause is entirely outside your control. That was the situation I found myself managing with a third-party construction platform integration that had been built directly into our main application.
The integration worked by fetching a 2-legged OAuth token at application bootstrap. The token was cached in memory and refreshed only on expiry — a reasonable design in isolation, but one with a catastrophic single point of failure: if the upstream platform was unavailable when the application started, the bootstrap routine failed, and the entire application failed to start with it. Because the main application serves global teams across India, Belgium, and the United States, an outage that occurred overnight in US Eastern time meant that by the time our team came online in the morning, colleagues across two other continents had already lost several hours of productive work waiting for the system to recover. The upstream platform averages roughly 21 incidents per month, with a median outage resolution time of approximately two hours. This was not a rare edge case. It was a recurring operational reality.
The integration itself covered a meaningful surface area — project creation, user provisioning, document upload, folder management — but from the main application’s perspective, it was just another synchronous dependency. And that co-location was the architectural mistake.
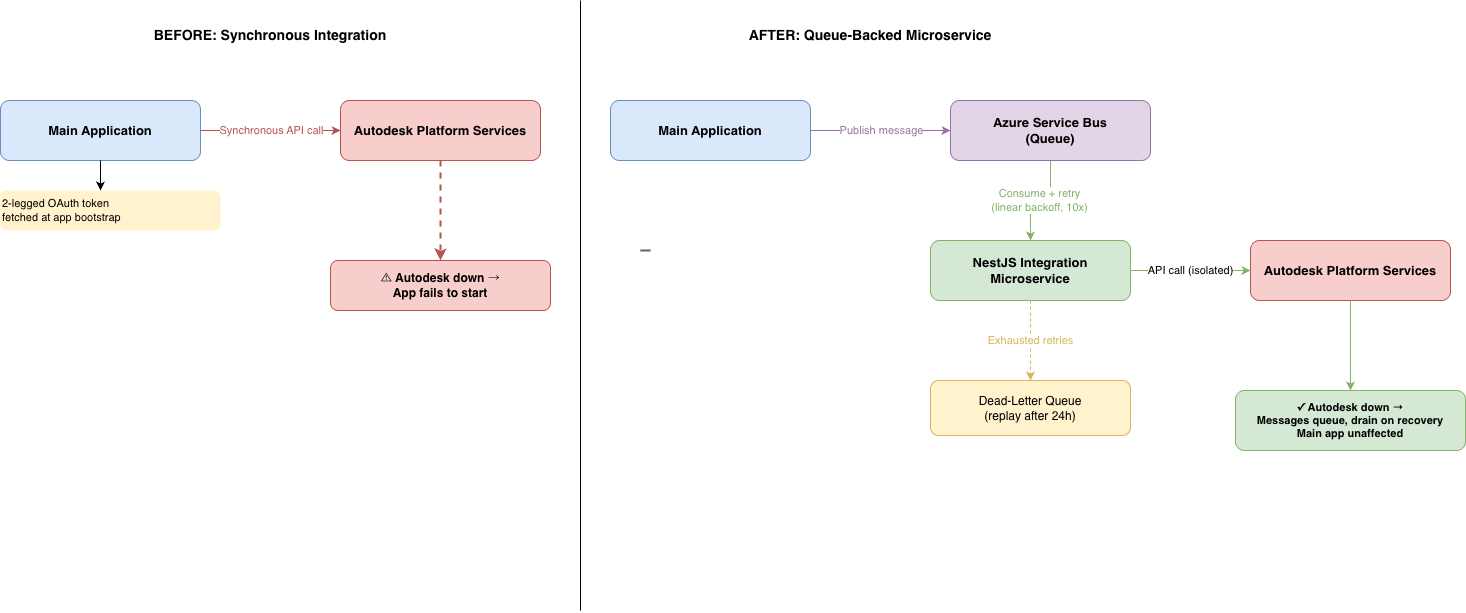 Figure 1: Left — the original architecture, where a token fetch failure at bootstrap brought down the entire application. Right — the microservice architecture, where the main application publishes to a queue and is fully decoupled from upstream availability.
Figure 1: Left — the original architecture, where a token fetch failure at bootstrap brought down the entire application. Right — the microservice architecture, where the main application publishes to a queue and is fully decoupled from upstream availability.
Why a Circuit Breaker Wasn’t Enough
The standard response to a flaky dependency is to wrap it in a circuit breaker: detect failure, open the circuit, fail fast, and let the system degrade gracefully rather than cascade. It is good practice, and in many contexts it is the right answer. Here, it was not.
The main application was already heavily loaded — it is a globally accessed platform supporting active teams across multiple regions simultaneously. Introducing circuit-breaker overhead, state management, and health-check polling for an external dependency on top of that existing load would have added complexity and resource consumption to a system that was already under pressure. More importantly, a circuit breaker would have changed the failure mode from “application crashes” to “application degrades gracefully and drops requests,” but it would not have changed the fundamental problem: the main application was still coupled to the upstream. When the upstream was down, users would still be blocked from completing work that depended on that integration, just with a cleaner error message.
The real problem was not how the application handled failure. The real problem was that the application was responsible for handling it at all. The integration needed to be separated into its own failure domain — a system boundary where upstream instability could be absorbed, queued, and replayed without the main application ever needing to know anything had gone wrong.
The Design Decision: Extraction Into a Dedicated Integration Microservice
The architectural decision was to extract the entire integration into a standalone NestJS microservice. NestJS was the right fit here: the main application was already a Node.js ecosystem, the team had existing familiarity with the framework, and NestJS has first-class support for message-queue-based transport via its microservices module — which was central to the design.
The key design principle was not just process isolation but failure domain isolation. A separate process that still makes synchronous calls back to the same upstream, and propagates failures back to the caller, is not meaningfully more resilient than the original architecture. True isolation means that the main application’s operational health has zero dependency on whether the upstream platform is available at any given moment. The main application’s only responsibility is to publish a message describing the work to be done. What happens after that — the API calls, the retries, the backoff, the eventual success or structured failure — is entirely the microservice’s concern.
The token lifecycle moved with the integration. The 2-legged OAuth token is now fetched and cached within the microservice, scoped per API call type, and has no footprint in the main application at all. Application bootstrap in the main system no longer involves any call to the upstream platform.
Making It Resilient: Queue-Backed Async Processing With Azure Service Bus
With the integration extracted, the next decision was the communication pattern between the main application and the microservice. Azure Service Bus was the natural choice: the platform already runs on Azure, Service Bus is a first-party managed offering with strong delivery guarantees, and its topic-and-queue model maps cleanly to the integration’s operational patterns — some operations are triggered by business events published to topics, others are invoked via dedicated queues.
The processing model is fully asynchronous. When the main application creates a project or triggers a document upload, it publishes a message to the appropriate Service Bus queue and returns immediately. The microservice consumes messages independently, executes the upstream API calls, and handles all the complexity of interacting with an unstable platform without surfacing any of that complexity to the caller.
When the upstream platform is unavailable — which, as noted, happens with notable frequency — Service Bus message delivery semantics ensure that messages are not lost. The microservice attempts delivery with a linear backoff strategy, retrying up to ten times before moving the message to the dead-letter queue. Critically, those ten retry attempts happen over an extended window, which means that outages of typical duration are fully absorbed: the message is eventually processed once the upstream recovers, and the main application never receives a failure signal. In practice, I have watched this play out in real production incidents multiple times. The upstream platform goes down, the queue depth grows, the platform recovers, and the queue drains — the main application’s users experience none of it.
Dead-Letter Handling and Idempotent Replay
Not every failure is transient. Messages that exhaust all retry attempts are moved to the dead-letter queue, where they wait for a separate processing pass that runs after a 24-hour hold period. This delay is deliberate: it provides a window for the upstream platform to recover from extended incidents before the message is retried a final time.
The dead-letter consumer includes an idempotency check that is worth describing in some detail, because it is the component that makes the replay semantics trustworthy rather than merely convenient. Before reprocessing a dead-lettered message, the consumer checks whether the operation described in the message has already been completed — for example, whether a project was successfully created in the upstream system during an earlier partial attempt, or whether a document was already uploaded. If the operation is found to be complete, the message is acknowledged and discarded without performing the API call again. This prevents duplicate creation and data integrity issues that would otherwise arise from replaying messages against an API that has no native idempotency guarantees on certain endpoints.
This pattern — dead-letter queue with hold period plus idempotency check on replay — is one of the more consequential design decisions in the system. It is what allows the team to trust that no work will be lost during an extended upstream outage, and equally that no work will be duplicated when the system recovers and replays queued operations.
The measure of a resilient integration is not how it behaves when everything works. It is whether operations are guaranteed to complete exactly once, even when the upstream fails repeatedly.
The Outcome: Upstream Outages Became Invisible
The clearest measure of success for this architecture is negative: the main application no longer appears in post-incident reviews for upstream outages. The upstream platform continues to have incidents at roughly the same cadence as before. The difference is that those incidents are now the microservice’s problem to manage, not the main application’s problem to propagate to users.
Teams in India and Belgium no longer arrive at the start of their working day to find a system that failed to start overnight because of an upstream token fetch. The main application starts cleanly, operates independently of upstream availability, and trusts the microservice to fulfill its queued work when conditions allow. I have observed this play out across multiple real incidents since the service went live: the queue absorbs the failure, the platform recovers, and the backlog drains without any manual intervention or user-visible disruption.
The architectural shift also produced a secondary benefit that was not part of the original motivation: the integration is now far easier to reason about, test, and operate independently. Its deployment lifecycle is separate from the main application, its failure modes are scoped and observable, and its operational runbook is self-contained. These properties compound over time — each new capability added to the integration inherits the same reliability guarantees by default, rather than requiring bespoke defensive coding.
Key Takeaways
- Co-locating a third-party integration with your main application couples your application’s availability to the upstream’s reliability. If the upstream is unstable, extraction into a dedicated microservice is a stronger architectural response than defensive patterns applied to the host application.
- A circuit breaker changes how a failure is handled. Extracting to a queue-backed microservice changes whether the failure is visible to your application at all. These are meaningfully different outcomes.
- Azure Service Bus dead-letter queues with a structured hold period and idempotency checks on replay provide exactly-once delivery semantics even across extended upstream outages — but only if the idempotency logic is explicitly built into the consumer.
- The success of this pattern is best measured by what stops happening: outage-driven application downtime, productivity loss for globally distributed teams, and manual recovery operations after upstream incidents.
Harshit is an Associate Principal Engineer with a decade of experience in enterprise-scale distributed systems. This post reflects work done in production environments.
Ideation and creation by human, written and formatted by AI