Defend What You Built: Winning an Architecture Decision as the New Person
How I defended a production-hardened internal integration service against a third-party iPaaS platform — and why the architecture decision came down to failure surface, not features.

There is a particular kind of meeting that tests you early in a new role. Everyone in the room has context you don’t have yet. A vendor evaluation is already in motion. The path of least resistance is to nod along, approve the new tool, and let the chips fall. I chose a different path — I came prepared with a formal architectural comparison, and I argued against introducing a third-party platform in favor of a service I had designed from scratch. This post is about that decision, the technical reasoning behind it, and what the process taught me about cross-team influence when you haven’t yet earned the room’s trust.
The Problem: Connecting a New System of Record to an Unstable Upstream
A large industrial manufacturing enterprise was migrating its project lifecycle management off a spreadsheet-based workflow tool and onto Salesforce. On the surface, this is a routine modernization. The complexity came from the downstream dependency: every project created in Salesforce needed to be provisioned in full inside an industry-leading construction management platform — including project creation, member access provisioning, and phased document delivery across three distinct lifecycle stages.
The construction management platform’s APIs are, to put it charitably, unreliable. Independent monitoring consistently shows approximately 21 incidents per month, with a median duration exceeding two hours per incident. This is not exceptional — it is the expected operating environment. Any integration architecture for this system has to be designed around the assumption that the upstream will be unavailable for significant stretches of time, and that retry logic, dead-letter handling, and idempotency are not nice-to-haves. They are load-bearing requirements.
The previous integration had been built to absorb exactly this reality. The question was whether the new architecture would preserve that resilience or trade it away for the appeal of a faster initial build.
The Service I Had Already Built
Over a year before this meeting, I designed and built the internal integration service from scratch. It is a NestJS microservice backed by a cloud message queue, with a relational database as the persistence layer for all project correlation state. It owns every interaction with the construction management platform — nothing else in the stack calls those APIs directly.
The service handles three categories of work, all of which are harder in practice than they appear on a diagram.
Project creation and identity management. When a new project is initiated, the service generates an internal project identifier and project number before doing anything else. This number is used as the project name in the construction platform from day one, which means there is no rename step required at any later stage. The identifier becomes the universal correlation key across all systems, and a project correlation record is written immediately after platform project creation succeeds — this record is the single source of truth for all cross-system joins throughout the project lifecycle.
Member provisioning. Access control in the construction platform is driven by group membership, and group resolution is non-trivial. Multiple mapping tables are consulted to determine which groups a user should be added to based on project type and region. The service is rate-limit-aware — it respects the platform’s retry signalling rather than hammering a throttled endpoint. Critically, it treats “user already a member” as a soft success rather than an error, which is a deliberate idempotency decision that prevents retry noise from becoming incident noise.
Document delivery via a multi-step pipeline. File delivery to the construction platform is not a single API call. The service executes a multi-step pipeline: creating a storage location, obtaining a signed upload URL, streaming the file bytes to that URL, completing the upload transaction, and then determining whether to create a new document item or register a new version of an existing one. This pipeline retries with backoff on transient failures and routes to a dead-letter queue with alerting on permanent failure. It has been handling production file volumes for over a year.
This is what was on the table when the vendor evaluation began.
Option A: The Case for a New Integration Platform
The proposal to introduce a third-party iPaaS platform had genuine merit, and I want to represent it honestly.
The argument was essentially: Salesforce is now the system of record, and purpose-built integration platforms exist for exactly this kind of event relay. They offer pre-built connectors, a low-code recipe model, and they reduce the implementation burden on engineering teams. For a team evaluating how to staff and maintain a growing integration surface, offloading to a managed platform has real operational appeal. The initial lean in the room was toward this option.
I was new to the team. The people in that room did not yet have a basis for trusting my judgment over a vendor’s product sheet. That is a fair starting position — it is how healthy engineering organizations should behave with engineers they don’t know yet.
Why I Pushed Back: The Argument Against Rebuilding Working Logic
I prepared a formal Option A versus Option B comparison document before the meeting. The argument I made had three parts.
First: production-hardened logic does not transplant for free. The internal service had been absorbing the construction platform’s instability for over a year. The retry backoff behaviour, the idempotency contracts, the dead-letter routing, the multi-step upload pipeline — none of this was designed in isolation. It was shaped iteratively by real failure modes encountered in production. Rebuilding equivalent behaviour inside a third-party platform’s recipe model meant re-learning those failure modes from scratch, in a configuration language I did not own, on top of an upstream that would surface those failures immediately and without warning.
Second: the failure surface compounds when you stack unproven platforms on unstable upstreams. The construction management platform generates ~21 incidents per month. Introducing a new iPaaS layer adds an independent failure domain on top of that. When something goes wrong at 2am — and something always does — the on-call engineer now has to determine whether the failure originated in the Salesforce event, the iPaaS platform’s recipe execution, its connector to the construction platform, or the platform itself. With the proposed architecture, the failure domain is explicit: either the event bridge failed to relay the event, or the internal service failed to process it. The diagnostic surface is narrower by design.
Third: a new vendor contract for zero net capability gain. Licensing a new iPaaS platform to handle the Salesforce-to-platform connection adds recurring cost — base licensing plus per-connection fees — for a capability the internal service already delivered. MuleSoft, already in use, is fully capable of streaming large files from Salesforce without the blocking concerns that had been raised in pre-meeting analysis about other platforms. The incremental cost of a new vendor was not buying the architecture anything it didn’t already have.
The room aligned on keeping the internal service as the ACC interaction layer, with MuleSoft acting as the event bridge between Salesforce and the internal service. Not immediately — there were legitimate questions about whether MuleSoft could handle large file streaming reliably, and whether the internal service’s API surface was ready to accept a new trigger source. Both were answerable in the meeting. Extending the service to accept MuleSoft-originated events rather than webhook-originated events was a well-scoped change, not a rewrite.
The Architecture We Agreed On
The agreed architecture routes as follows: Salesforce publishes platform events on project lifecycle changes. MuleSoft listens to those events and relays them — with validated payloads — to the internal integration service. The internal service executes all construction platform operations and returns status updates to Salesforce via MuleSoft. The construction platform never receives a call from anything other than the internal service.
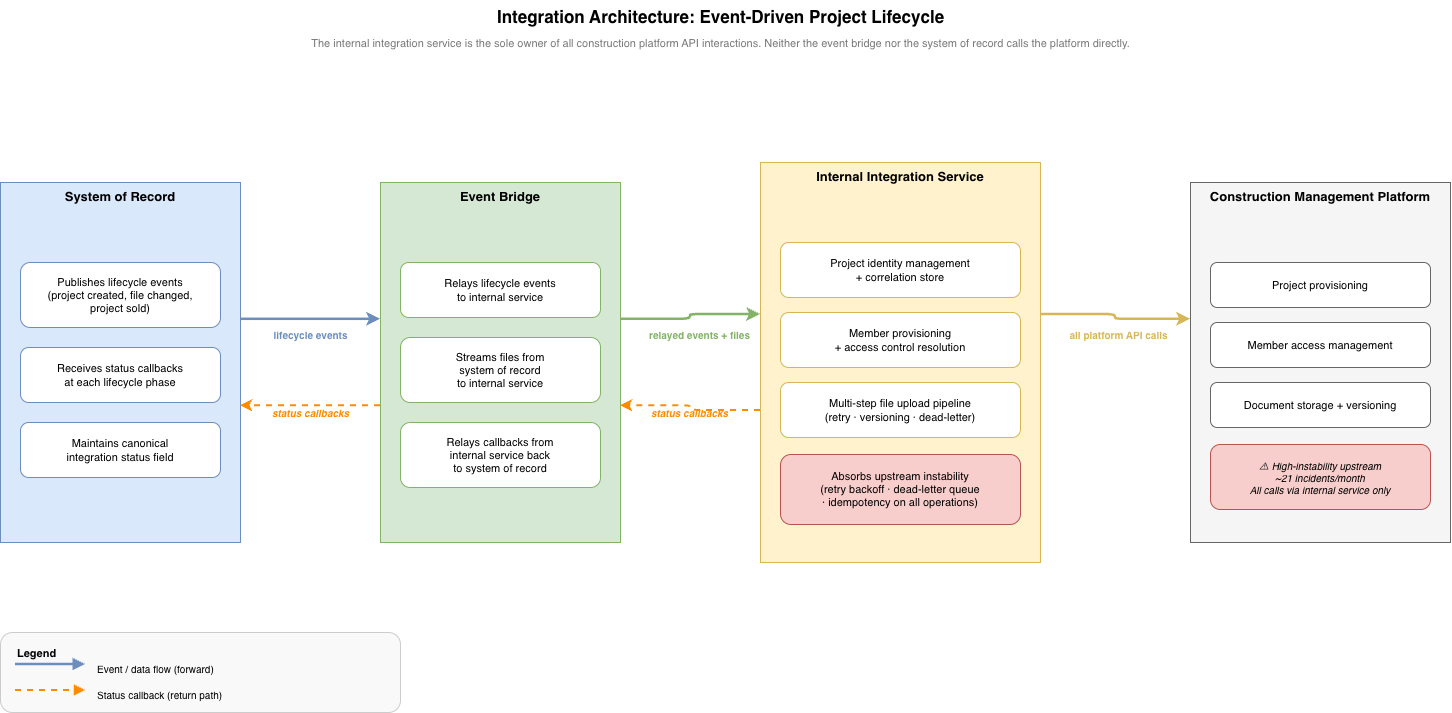 Figure 1: The agreed integration architecture. MuleSoft operates as a thin relay layer. All construction platform API logic — retry, idempotency, dead-letter handling, and file pipeline execution — remains exclusively owned by the internal integration service.
Figure 1: The agreed integration architecture. MuleSoft operates as a thin relay layer. All construction platform API logic — retry, idempotency, dead-letter handling, and file pipeline execution — remains exclusively owned by the internal integration service.
The cleaner the responsibility split, the easier the system is to operate. Every team knows which system they own and what they are responsible for. Salesforce owns the events and the canonical status field. MuleSoft owns reliable event relay and file streaming. The internal service owns every interaction with the construction platform. No team steps into another team’s domain.
The integration is also bi-directional. The internal service does not only receive events — it returns data to Salesforce at each phase of the project lifecycle: project identifiers after creation, member confirmation signals to unblock document uploads, and per-file upload confirmations throughout the quoting lifecycle. This return path is what makes the canonical status field on the Salesforce record meaningful — it reflects the actual state of the integration, not just the state of the Salesforce record itself.
Event Ordering and the Sequencing Problem
The most underestimated design problem in multi-system project provisioning is not the happy path — it is the ordering constraints between phases. Get the sequence wrong and the failure is silent: no exception, no alert, just data that is wrong in a way that only becomes visible to an end user.
The project lifecycle has three hard phase gates, each of which must be confirmed before the next phase begins.
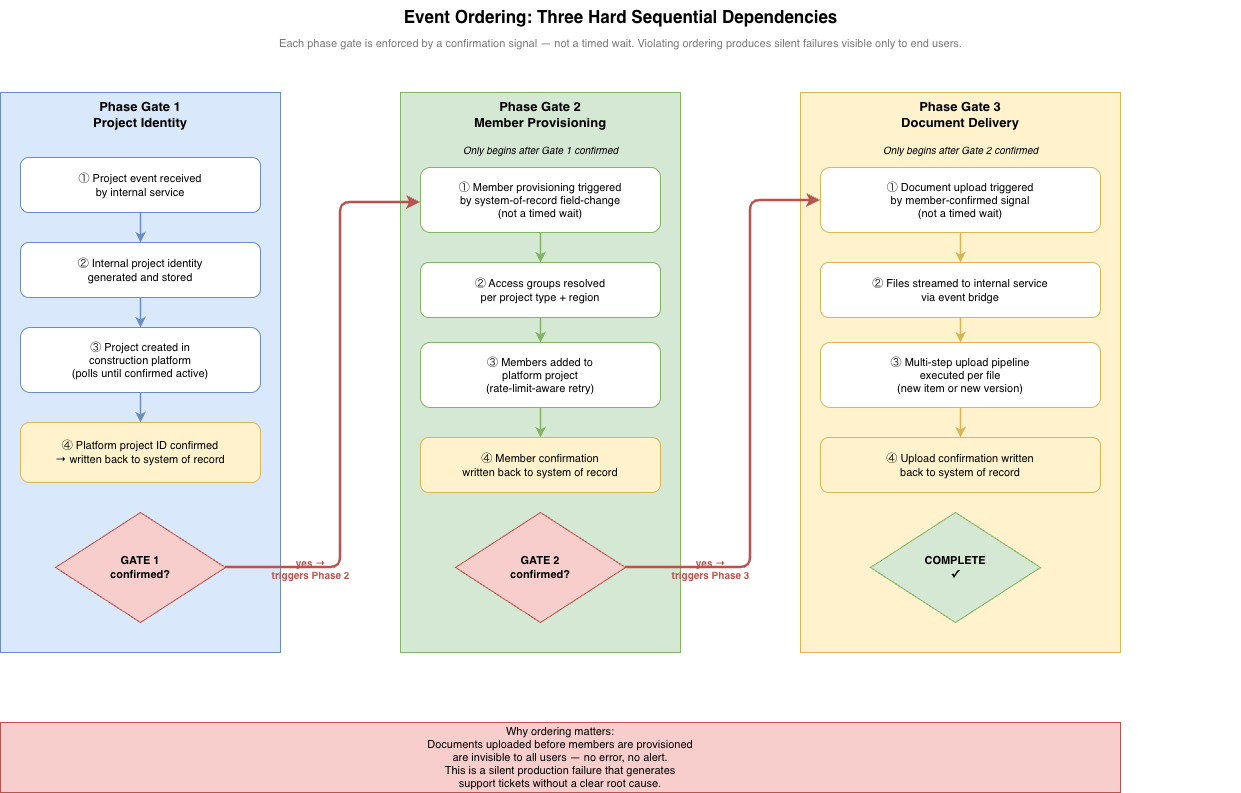 Figure 2: The three phase gates enforced in the integration. Each gate is triggered by a confirmation signal written back to the system of record — not by a timed wait. Skipping a gate produces a silent production failure.
Figure 2: The three phase gates enforced in the integration. Each gate is triggered by a confirmation signal written back to the system of record — not by a timed wait. Skipping a gate produces a silent production failure.
Gate 1: project identity before platform provisioning. The internal service must generate and store the project’s internal identifier before creating the project in the construction platform. This identifier becomes the project’s name in the platform on day one — there is no rename step later. All downstream operations are keyed against this identifier.
Gate 2: platform project confirmed before member provisioning. The event bridge must not trigger member provisioning until the construction platform project identifier has been confirmed and written back to the system of record. This gate is enforced by a field-change event on the system of record — not a timed wait. A timed wait is either too short, causing race conditions, or unnecessarily slow, adding latency to every project creation. The field-change event is neither.
Gate 3: members confirmed before document upload. This is the most operationally consequential gate. Documents uploaded to a construction platform project before members are provisioned are invisible to all users. There is no error. There is no alert. The files exist in the platform but no one can see them — which generates a support ticket, requires manual investigation, and damages trust in the integration. The internal service must not begin document upload until member provisioning completion has been confirmed and written to the system of record.
Each gate confirmation flows back through the event bridge to the system of record. This makes the Salesforce record the single source of truth for where any given project stands in its provisioning lifecycle — readable by any team without needing to query the internal service directly.
Designing for Failure: Idempotency, Retries, and the Dead-Letter Contract
The construction management platform generates roughly 21 incidents per month. This figure is not a reason to avoid building on the platform — it is a design input. The internal service was built with the assumption that any given API call may fail on first attempt, and the architecture reflects that at every level.
Every mutating operation in the internal service is idempotent by design. If the event bridge retries a project creation call because a response was lost in transit, the service checks its correlation store before creating anything. If a record already exists, it returns the existing identifiers. If the platform returns a uniqueness error on project creation, the service retrieves the existing project rather than surfacing a failure. Member provisioning treats “user already a member” as success. The idempotency contract means that retrying any operation in any failure scenario produces the correct end state — not a duplicate, not a crash.
Permanent failures — operations that have exhausted their retry budget — are not silently dropped. They are routed to a dead-letter queue with alerting. An operator can inspect the failed message, understand which step failed and why, and replay it once the upstream recovers. This is the operational safety net that a recipe-based platform would have needed to configure from scratch, and which the internal service had already validated in production.
The most important thing a resilient integration service does is not handle the happy path — it is make failures visible, bounded, and recoverable.
This matters particularly in a multi-team integration. Without a clear dead-letter contract and shared status visibility, a failure in the internal service looks like a silent black hole to every team upstream. The canonical status field on the system of record, updated by the internal service at each phase gate, solves this problem — it makes the internal service’s state legible to teams who have no access to its internals.
What the Risk Register Taught Me About Cross-Team Influence
The architecture document I brought to that meeting included a detailed risk register. This was not defensive paperwork — it was the most useful communication tool I had.
When you are new to a team and you need a room of experienced engineers to trust a technical position, the fastest path is not to assert confidence. It is to demonstrate that you have already thought through the failure modes they are about to raise. A risk register does this structurally. Each entry I documented named a failure mode, its severity, its owner, and its mitigation. Distributed failure across provisioning phases — the scenario where a platform project exists but member provisioning has failed, leaving documents uploaded with no one to see them — was the highest-severity item, owned explicitly by the internal service team, with a concrete mitigation tied to the gate confirmation design.
Naming risks at that level of specificity, before anyone else raised them, changed the dynamic in the room. The conversation shifted from “can we trust this service?” to “let’s make sure the phase gates are enforced correctly.” That is a much more productive conversation. The risk register also established a clear boundary between what had been decided and what remained open — which questions needed answers before implementation could begin, and which team was responsible for each answer.
For engineers who are new to a team and need to build credibility quickly: a formal risk analysis that anticipates the hard questions is worth more than any amount of confident presentation. The work speaks for itself, but only if you show it.
Key Takeaways
- Don’t rebuild production-hardened logic in an unproven platform. If a service has been absorbing a difficult upstream for over a year, that accumulated resilience has real value. The cost of rebuilding it elsewhere is not just implementation time — it is re-encountering every failure mode that shaped the original design.
- Failure surface compounds when you stack new platforms on unstable upstreams. Every additional system in a failure path is an independent failure domain. Keep the failure surface as small as the architecture allows, especially when the upstream is known to be unreliable.
- Event ordering is a first-class design problem in multi-system integrations. Hard sequential dependencies must be enforced by confirmation signals, not timed waits. Silent ordering failures — documents visible to no one, members provisioned to no project — are the hardest class of production bug to diagnose.
- Idempotency is not optional when the upstream is unstable. Every mutating operation that may be retried must produce the same correct end state regardless of how many times it executes. Design for this from the start; retrofitting it is significantly harder.
-
A risk register is a credibility artifact, not just a planning tool. When you are new to a room, naming failure modes before others raise them demonstrates exactly the kind of thinking that earns trust faster than any amount of confidence signalling.
Harshit is an Associate Principal Engineer with a decade of experience in enterprise-scale distributed systems. This post reflects work done in production environments.
Ideation and creation by human, written and formatted by AI