What an Agentic Coding Workflow Can't Decide for You
An agentic coding workflow can plan and build across repos, but it can't decide the architecture or recover when reality breaks. Here is where judgment lives.

The job an agentic coding workflow doesn’t do
The interesting question about agentic coding tools is no longer whether they can write code across a large codebase. They can. The question is what part of the work stops being delegable once the tool is good enough to delegate the rest. I spent a multi-month epic — five backend repositories, one coordinated feature spanning all of them — running most of the planning, research, and implementation through an agentic coding workflow. The tool earned its place. But the more capable it got at the executional middle, the sharper the boundary became around the part it could not do: decide.
This is the shift worth naming. An agentic coding workflow moves the senior engineer’s work away from producing code and toward governing generated plans. And governance is not a feature you enable — it is judgment you supply at the points where the tool is structurally unable to. Across a real lifecycle, those points are not evenly distributed. They cluster at the front, before the tool runs at all; at the architecture layer, where the tool plans around decisions it never originates; and at the back, when something the tool never modeled breaks and the recovery is entirely yours.
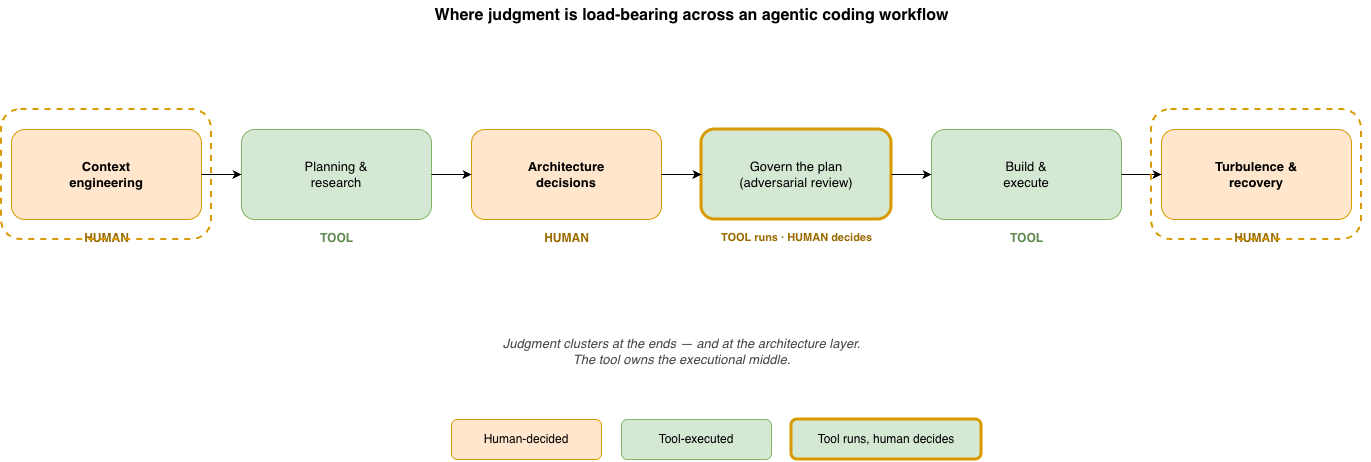 Figure 1: Judgment clusters at the ends of the lifecycle — context engineering up front, recovery at the back — and at the architecture layer. The tool owns the broad executional middle. Where the band is human, the tool cannot decide for you.
Figure 1: Judgment clusters at the ends of the lifecycle — context engineering up front, recovery at the back — and at the architecture layer. The tool owns the broad executional middle. Where the band is human, the tool cannot decide for you.
Context engineering is the precondition, not the afterthought
An agent starts blind. It does not know your five repositories, the contracts between them, the conventions that are load-bearing versus incidental, or the decisions that were settled long before it arrived. Point it at that cold and it will produce something plausible and wrong, confidently. The first piece of judgment happens before the tool does anything: deciding what it needs to know and writing that down well.
So I treated context as something to engineer, not assume. Before any planning run, I built a base instruction file and a per-repository handoff document — each one a deliberate, curated account of what that service owns, what it must not touch, the patterns to follow, and the cross-repo contracts it has to respect. This is unglamorous work and it is the work most accounts of AI-assisted development skip entirely. But the quality ceiling of everything the tool produces downstream is set here. An agent’s output is capped by the context you give it, and curating that context — choosing what is relevant, what is misleading, and what is missing — is judgment that does not delegate. You cannot ask the tool to engineer its own context, because deciding what matters is the thing you are bringing.
The architecture the tool won’t invent for you
Once it has context, an agentic workflow is genuinely strong at breadth: it located the relevant files across all five repos, traced data flows end to end, and surfaced gaps a human would have found eventually but slower. What it did not do — what it does not do — is originate the architectural decisions the plan is built around. It plans around your architecture; it does not invent it.
Two of the load-bearing decisions in this epic were mine, and the tool’s plan formed downstream of them rather than producing them. The first was a batch-tracking construct that treats a multi-file upload as a single correlated unit, so the system can reason about “this whole batch succeeded or didn’t” rather than tracking files as unrelated events. The second was insisting we capture the downstream system’s document identifiers after each upload completed — so the result stays traceable afterward, not just successful in the moment. The tool was optimizing for “make the upload work.” I was optimizing for “make the outcome correlatable and auditable later,” which is a different objective, and one a plan-generator does not reach for on its own. These were design calls, made for reasons rooted in how the system would have to be operated and debugged for years. The tool implemented them well. It would never have proposed them.
This is the same kind of judgment I wrote about in the context of owning an architecture decision under pressure — the part of the role that does not change no matter how much execution gets automated.
Governing the generated plan adversarially
The right posture toward a generated plan is not trust — it is adversarial review. A plan that reads coherently can still be wrong: a referenced method that does not exist, a migration that claims to add columns already present, a step that optimizes for the wrong objective. So before any of it ran, the plan got attacked. I was using Spectre, a planning-and-review plugin for Claude Code, which runs a multi-lens review pass over a generated plan — checking it for unsupported existence claims, unverifiable steps, and overengineering. That pass is valuable, and I would not run a serious multi-repo plan without one like it.
A tool can tell you a plan is internally consistent. It cannot tell you the plan is right for a system it has never had to operate.
But the review surfaces findings; it does not get the final say. At one point the review flagged a unification step in the plan as a candidate for removal — reasonable on its face, since it added scope. I kept it, deliberately, because it resolved a real inconsistency across the repos that would have cost more later than the scope cost now. That is the shape of the whole relationship: the tool runs the adversarial pass, and I decide which findings to action, which to override, and which to keep against its recommendation. The review is leverage on my judgment, not a replacement for it.
When reality breaks an assumption the tool never modeled
Then the part no plan survived. Mid-build, after the workflow had been deployed and was moving real files, a large upload failed against a constraint nothing in the plan had modeled: a message broker’s payload size ceiling, made worse by encoding inflation that pushed large files past a limit they appeared to fit under. The tool had planned a clean, internally consistent transport. The transport was wrong, and no amount of re-running the plan would have told it so, because the failing assumption lived outside everything it had been given.
The recovery was entirely human. I drove the redesign end to end — re-architecting the transport so small payloads travel inline and large ones travel by reference, with the threshold set where it actually belonged. I documented the technical detail of that pivot separately, in the size ceiling that broke the original transport. What matters here is the division of labor: I made the new architectural decision, and then the tool re-planned against it — regenerating the task breakdown to match a design it had no part in choosing. It is an excellent navigator once you have decided where the ship is going. When the map turns out to be wrong, it cannot pick the new heading. You do.
How the senior role actually changes
The honest summary is not that the tool made me faster, though it did. It is that the tool relocated where my judgment had to be exercised. It absorbed the executional middle — the file-finding, the tracing, the mechanical implementation — and in doing so it made the non-delegable parts more visible, not less. Judgment moved earlier (engineering the context before the tool runs), higher (the architecture the plan is built around), and harder (the recovery when reality breaks an assumption the tool never had).
That is a more demanding role, not a diminished one. The leverage is real and the output scales. But the parts that determine whether the system is right — and whether it can be operated and recovered when it isn’t — stay exactly where they were. An agentic coding workflow changes what you spend your hours on. It does not change who has to decide.
Key Takeaways
- An agentic coding workflow moves the senior engineer’s work from writing code to governing generated plans — and governance is judgment, not a feature you turn on.
- Context engineering is the precondition for everything downstream. The quality ceiling of generated output is set by the context you curate before the tool runs, and deciding what matters does not delegate.
- Tools plan breadth well but do not originate architecture. The load-bearing design decisions — and the objectives behind them, like traceability and correlation — are yours to supply.
- Treat a generated plan as a draft to attack, not a result to accept. Run an adversarial review, but keep the final say: action, override, or reject its findings on your judgment.
- When reality breaks an assumption the tool never modeled, recovery is human. The tool can re-plan against your decision; it cannot make the decision.
Harshit is an Associate Principal Engineer with over a decade of experience in enterprise-scale distributed systems. This post reflects work done in production environments.
Ideation and creation by human, written and formatted by AI