Message Queues Have a File Size Ceiling: Design Around It
A message queue file size limit, worsened by base64 inflation, breaks large file uploads. Here's how a size-gated transport routes big payloads safely.

The size ceiling nobody budgets for
When you put a file-transfer flow behind a message broker, the design reads clean on a whiteboard: a producer drops a message carrying the file, the broker holds it durably, a consumer picks it up and pushes the file downstream. It decouples the two sides, gives you retries for free, and survives the downstream system being temporarily unavailable. I designed exactly this on Azure Service Bus to move documents from an upstream quoting workflow into a downstream document-management system.
It worked for everything I tested. Then, during build-out, a large file failed before the flow ever reached production. The cause was not a bug in my code — it was a load-bearing assumption I had never written down: that a file small enough to store is small enough to send inline through the queue. Those are not the same constraint, and the gap between them is the message queue file size limit. This is a constraint most queue-backed designs inherit silently and discover late.
Why base64 inflation breaks the message queue file size limit
Two facts collide here. First, message brokers cap the size of a single message, and the cap is smaller than people assume. On Azure Service Bus, the Standard tier limits a message to 256 KB. The Premium tier defaults to 1 MB and supports payloads up to 100 MB only when you explicitly enable large-message support, and only over the AMQP protocol — not SBMP or HTTP. So even on the largest configuration, the inline ceiling is 100 MB, not unbounded.
Second, you rarely send raw bytes through a message. Binary file content gets base64-encoded so it survives a JSON message body, and base64 inflates the payload by roughly 33%. That inflation is the part that bites, because it means the largest file you can send inline is meaningfully smaller than the broker’s stated message ceiling — and small test files never reveal it.
| Raw file | After base64 (~+33%) | Under the 100 MB inline ceiling? |
|---|---|---|
| 10 MB | ~13 MB | Yes |
| 50 MB | ~66 MB | Yes — with headroom |
| 75 MB | ~100 MB | At the edge |
| 90 MB | ~120 MB | No |
A 90 MB document is well under the 100 MB message ceiling as a file, and well past it once encoded. The broker did exactly what it promised; my assumption about what “fits” was wrong.
Inline below the gate, by reference above it
The fix is to stop treating every file the same way. Below a size threshold, the message carries the encoded payload inline — fast, single-hop, nothing else to coordinate. Above the threshold, the message carries a reference to the file instead of the file itself: the producer writes the file to blob storage and puts a pointer in the message. The consumer reads the pointer and fetches the file out of band.
I set the gate at 50 MB of raw file size. That is a deliberate choice, not the broker’s maximum. A 50 MB file encodes to roughly 66 MB, which sits comfortably under the 100 MB inline ceiling with more than 30 MB of headroom for the message envelope, metadata, and encoding variance. Setting the gate at the theoretical edge — around 75 MB raw, which encodes to almost exactly 100 MB — would leave no margin for the rest of the message and would fail intermittently the moment any metadata grew. The threshold belongs below the cliff, not on it.
The size threshold is not a tuning parameter — it is the architectural decision. You set it where indirection earns its cost and where the inline path keeps its margin, not at the broker’s advertised maximum.
Streaming the reference instead of buffering it
Routing large files by reference solves the message-size problem but introduces a memory problem. The naive consumer downloads the referenced file fully into memory, then forwards it downstream. One large file is survivable; a handful arriving concurrently is how a service runs out of memory and falls over under exactly the load you built it to handle.
So the large-file path streams. The consumer opens a read stream from blob storage and pipes it straight to the downstream system without ever holding the whole file in memory. No Azure service does this stream-through for you as a managed primitive — blob storage stores the bytes and the downstream system accepts them, but the consumer is responsible for connecting the two as a stream rather than a buffer. That wiring is the part you own, and getting it wrong is invisible until concurrency exposes it.
Why the reference has to outlive the message
Routing by reference adds a constraint that is easy to miss: the pointer has to stay valid for as long as the message might live. A time-limited signed URL that expires in an hour seems generous until you remember what a queue actually does. A message can sit behind a backlog, get redelivered after a transient downstream failure, ride out retry backoff, or wait on a readiness delay before the consumer is even listening. If the signed URL expires inside that window, the message is now undeliverable through no fault of its own, and you have manufactured a poison message out of a perfectly good file.
I sized the signed URL’s lifetime to cover the worst-case time a message can spend in the system — backlog plus retry and backoff plus readiness delay — with margin, rather than to the happy-path delivery time. The reference must outlive the message, not the typical delivery. This is the sub-decision that separates a transport that works in a demo from one that survives a bad afternoon in production.
Why not route everything through the claim check pattern
The obvious objection is to skip the gate entirely and route every file by reference — the classic claim check pattern, applied uniformly. It is simpler to reason about: one path, no threshold, no branching.
I rejected it because the cost does not match the traffic. Large files were infrequent in this flow; the overwhelming majority of messages were small. Routing everything by reference would impose a blob write, a signed-URL mint, and a separate fetch on every single message — including the thousands that would have fit inline with room to spare. That is real latency and real operational surface added to the common case to serve the rare one. Size-gating pays the indirection cost only when a file actually needs it, and keeps the hot path a single hop. The pattern is right; applying it unconditionally is overkill. The judgment is in scoping it to where it earns its keep.
This sits alongside the resilience patterns I wrote about in a queue-backed integration microservice — same broker, same architecture, a different class of constraint. Together they describe how I think about putting real workloads behind a message queue. For the underlying limits, Microsoft documents the per-tier message ceilings in the Azure Service Bus quotas reference.
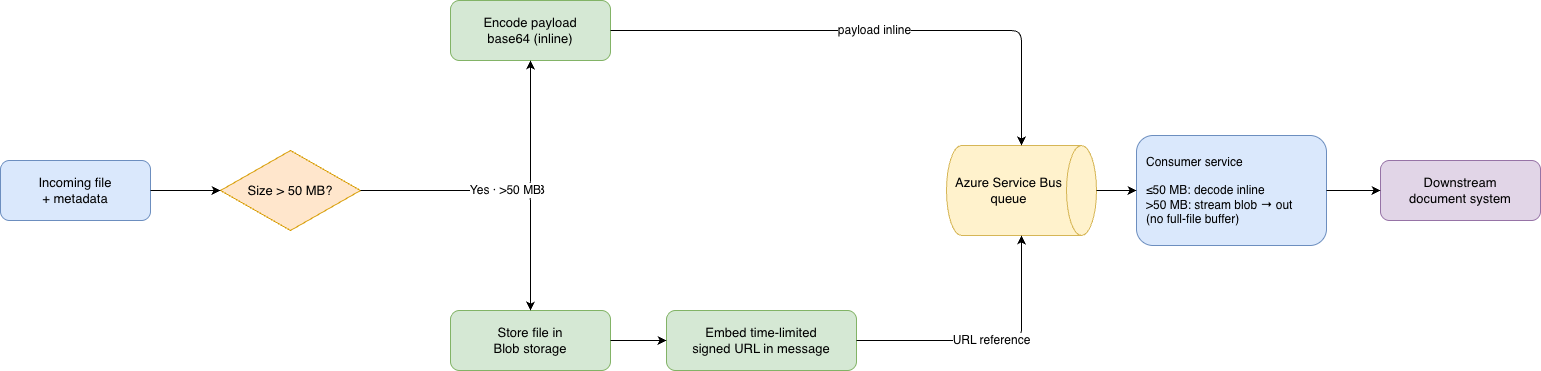 Figure 1: The size gate is the central decision. Files below the threshold ride inline as base64; files above it are stored in blob storage and referenced by a time-limited signed URL, which the consumer streams directly to the downstream system rather than buffering.
Figure 1: The size gate is the central decision. Files below the threshold ride inline as base64; files above it are stored in blob storage and referenced by a time-limited signed URL, which the consumer streams directly to the downstream system rather than buffering.
Key Takeaways
- A broker’s message-size limit is not your file-size limit. Base64 encoding inflates payloads by roughly a third, so the largest file you can send inline is well below the advertised message ceiling — and small test files will never show you the gap.
- Size-gate the transport: send small files inline and route large files by reference. Set the threshold below the broker’s ceiling with headroom for the message envelope, not at the theoretical maximum.
- Stream referenced files from storage to the downstream system instead of buffering them, or concurrency will turn a working consumer into an out-of-memory failure.
- A reference must stay valid for the worst-case lifetime of a message — backlog, redelivery, retry backoff, readiness delay — not the happy-path delivery time.
- The claim check pattern is correct but applying it to every message is overkill when large files are rare. Scope indirection to where it earns its cost.
Harshit is an Associate Principal Engineer with over a decade of experience in enterprise-scale distributed systems. This post reflects work done in production environments.
Ideation and creation by human, written and formatted by AI